六、Java 内存模型(Java Memory Model,JMM)#
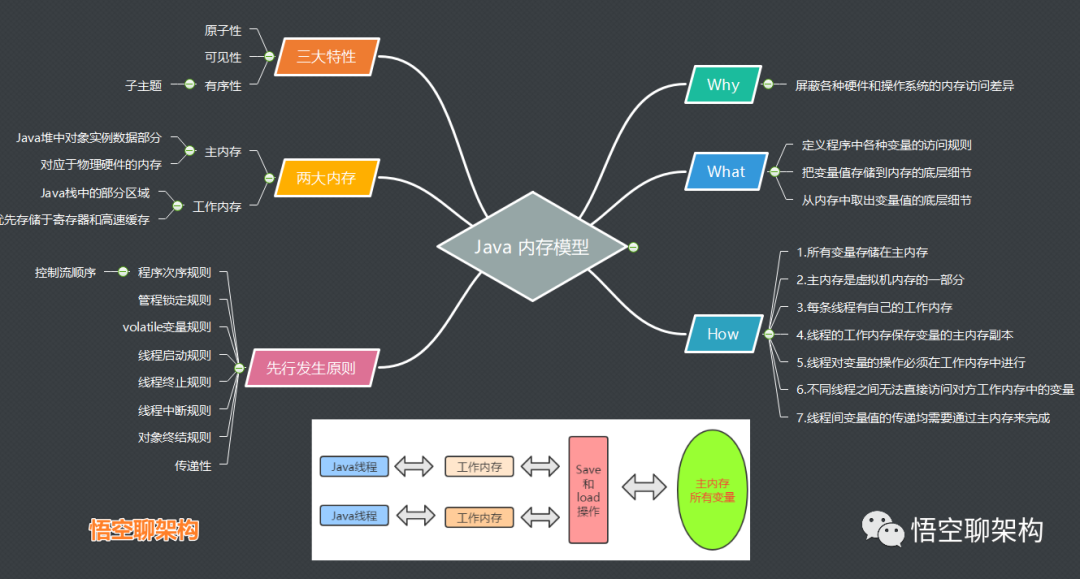
JMM 定义了 Java 程序中的变量、线程如何和主存以及工作内存进行交互的规则。
并发编程的线程之间存在两个问题:
- 线程间如何通信?即:线程之间以何种机制来交换信息
- 线程间如何同步?即:线程以何种机制来控制不同线程间发生的相对顺序
有两种并发模型可以解决这两个问题:
- 消息传递并发模型
- 共享内存并发模型
这两种模型之间的区别如下图所示:

Java 使用的是共享内存并发模型。
Java 共享内存并发模型#

- 主内存:Java堆中对象实例数据部分,对应于物理硬件的内存
- 工作内存:对应线程的虚拟机栈的部分区域,虚拟机可能会对这部分内存进行优化,优先存储在CPU的寄存器或高速缓存中。
在栈中的变量(局部变量、方法定义的参数、异常处理的参数)不会在线程之间共享,也就不会有内存可见性的问题,也不受内存模型的影响。而在堆中的变量是共享的,一般称之为共享变量。
所以,内存可见性针对的是堆中的共享变量。
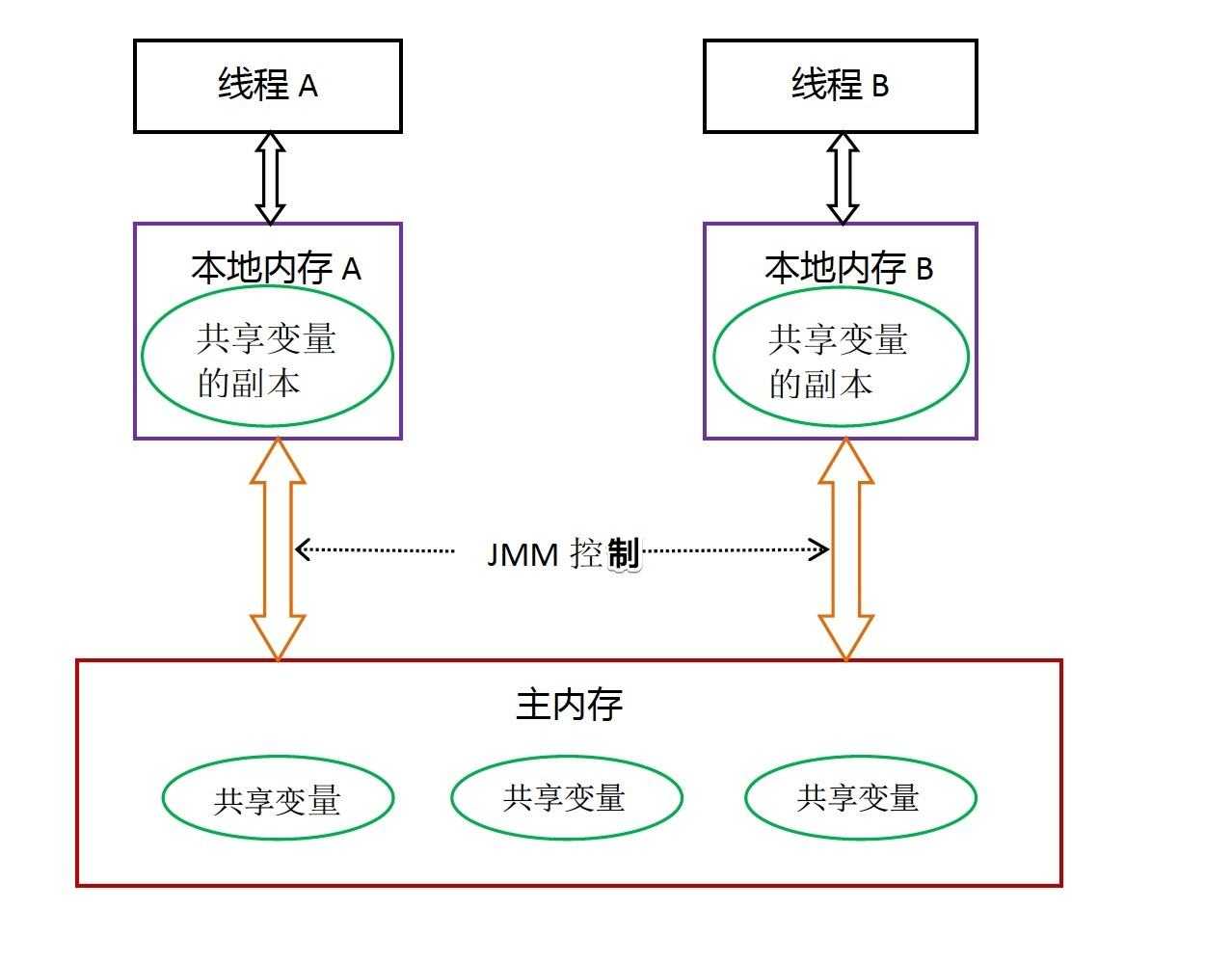
内存模型规定如下:
-
所有的变量全部存储在主内存(注意这里包括下面提到的变量,指的都是会出现竞争的变量,包括成员变量、静态变量等,而局部变量这种属于线程私有,不包括在内)
-
每条线程有着自己的工作内存(保存了一份该线程使用到的共享变量的副本),线程对共享变量的所有操作,必须在工作内存中进行,不能直接操作主内存中的数据。
也就是说,每一条线程如果要操作主内存中的数据,那么得先拷贝到自己的工作内存中,并对工作内存中数据的副本进行操作,操作完成之后,也需要从工作副本中将结果拷贝回主内存中,具体的操作就是
Save(保存)和Load(加载)操作。 -
不同线程之间的工作内存相互隔离,如果需要在线程之间传递内容,只能通过主内存完成,无法直接访问对方的工作内存。
那么如何保证内存可见性?怎么知道这个共享变量的被其他线程更新了呢?JMM 通过控制主存与每个线程的本地内存之间的交互,来提供内存可见性保证。
Java 中的 volatile 关键字可以保证多线程操作共享变量的可见性以及禁止指令重排序,synchronized 关键字不仅保证可见性,同时也保证了原子性(互斥性)。
在更底层,JMM 通过内存屏障来实现内存的可见性以及禁止重排序。为了程序员更方便地理解,设计者提出了 happens-before 的概念(下文会细讲),它更加简单易懂,从而避免了程序员为了理解内存可见性而去学习复杂的重排序规则,以及这些规则的具体实现方法。
重排序#
在编译或执行时,为了优化程序的执行效率,编译器或处理器常常会对指令进行重排序,有以下情况:
- 编译器优化重排,编译器在不改变单线程程序语义的前提下,重新安排语句的执行顺序。
- 指令并行重排,现代处理器采用了指令级并行技术来将多条指令重叠执行。如果不存在数据依赖性(即后一个执行的语句无需依赖前面执行的语句的结果),处理器可以改变语句对应的机器指令的执行顺序。
- 内存系统重排,由于处理器使用缓存和读写缓存冲区,这使得加载(load)和存储(store)操作看上去可能是在乱序执行,因为三级缓存的存在,导致内存与缓存的数据同步存在时间差。
指令重排可以保证串行语义一致,但是没有义务保证多线程间的语义也一致。所以在多线程下,指令重排序可能会导致一些问题。
顺序一致性模型与JMM的保证#
一、数据竞争(Data Race)与正确同步
- 数据竞争:当两个线程并发访问同一个变量,其中至少有一个是写操作,且这些访问没有通过 happens-before 关系进行排序时,就存在数据竞争。
- 如果程序中存在数据竞争,则其行为是未定义的(undefined behavior),运行结果不可预测、不可重现。
- 正确同步(如使用
synchronized、volatile、final、java.util.concurrent工具等)可以建立 happens-before 关系,从而消除数据竞争。
JMM 承诺:如果程序是正确同步的(即无数据竞争),那么其执行结果将与在顺序一致性模型中的某个执行结果一致。
二、什么是顺序一致性模型?
顺序一致性(Lamport, 1979)是一个理想化的内存模型,具有两大特性:
- 程序顺序性(Program Order): 每个线程内的操作必须按照代码顺序执行。
- 全局单一执行顺序(Global Total Order): 所有线程看到的操作执行顺序是一致的,且每个操作原子地、立即对所有线程可见。
举例: 线程 A:A1 → A2 → A3 线程 B:B1 → B2 → B3 在 SC 模型中,存在一个全局序列(如 A1 → B1 → A2 → B2 → A3 → B3),所有线程都观察到这个顺序。
三、JMM 为什么不直接实现顺序一致性?
因为顺序一致性会严重限制硬件和编译器的优化能力,导致性能大幅下降。
JMM 的设计哲学是在性能与正确性之间取得平衡:
在保证正确同步程序语义不变的前提下,允许尽可能多的重排序和优化。
具体差异如下:
| 特性 | 顺序一致性模型 | Java 内存模型(JMM) |
|---|---|---|
| 单线程内操作顺序 | 严格按程序顺序 | 允许重排序,但保证 as-if-serial(单线程结果不变) |
| 多线程可见性 | 所有操作立即全局可见 | 仅通过同步建立 happens-before 才保证可见性;否则,写操作可能滞留在本地缓存 |
| 操作原子性 | 所有内存操作原子 | long/double 的非 volatile 写操作可能不是原子的(JVM 规范允许拆分为两个 32 位写) |
| 执行结果一致性 | 所有执行都符合某个全局顺序 | 仅对无数据竞争的程序保证与 SC 某一执行等价 |
JMM要求编译器和处理器禁止会改变程序执行结果的重排序。
happens-before#
JMM使用happens-before的概念来定制两个操作之间的执行顺序。这两个操作可以在一个线程以内,也可以是不同的线程之间。
happens-before关系的定义如下:
- 如果一个操作happens-before另一个操作,那么第一个操作的执行结果将对第二个操作可见,而且第一个操作的执行顺序排在第二个操作之前;
- 两个操作之间存在happens-before关系,并不意味着Java平台的具体实现必须要按照happens-before关系指定的顺序来执行。如果重排序之后的执行结果,与按happens-before关系来执行的结果一致,那么JMM也允许这样的重排序。
程序员只要遵循happens-before规则,那他写的程序就能保证在JMM中具有强的内存可见性。
在Java中,有以下天然的happens-before关系:
- 程序顺序规则:一个线程中的每一个操作,happens-before于该线程中的任意后续操作。
- 监视器锁规则:对一个锁的解锁,happens-before于随后对这个锁的加锁。
- volatile变量规则:对一个volatile域的写,happens-before于任意后续对这个volatile域的读。
- 传递性:如果A happens-before B,且B happens-before C,那么A happensbefore C。
- start规则:如果线程A执行操作ThreadB.start()启动线程B,那么A线程的ThreadB.start()操作happens-before于线程B中的任意操作、
- join规则:如果线程A执行操作ThreadB.join()并成功返回,那么线程B中的任意操作happens-before于线程A从ThreadB.join()操作成功返回。
七、管程模型—synchronized 关键字与锁#
管程模型(Monitor) 是一种程序结构,用于管理对共享资源的并发访问。它的核心思想是:同一时刻,最多只有一个线程能执行管程中的代码。
一个完整的管程通常包含以下三部分:
组件 说明 1. 共享数据(Shared Data) 被多个线程访问的变量或资源(如队列、计数器等) 2. 互斥锁(Mutex / Lock) 确保同一时间只有一个线程能进入管程(即执行管程内的方法) 3. 条件变量(Condition Variables) 用于线程间的等待/通知机制 在 Java 中:
- 互斥锁 由对象的 Monitor(监视器) 实现;
- 条件变量 通过
Object.wait()/notify()/notifyAll()实现。
在Java多线程中,锁的概念都是基于对象的,因此也称它为对象锁。它采用互斥的方式让同一时刻至多有一个线程能持有对象锁。
还有一点需要注意的是,我们常听到的类锁其实也是对象锁。
Java类只有一个Class对象(可以有多个实例对象,多个实例共享这个Class对象),而Class对象也是特殊的Java对象。所以我们常说的类锁,其实就是Class对象的锁。
synchronized 关键字#
通常使用 synchronized 关键字来给一段代码或一个方法上锁。有以下三种形式:
// 关键字在实例方法上,锁为当前实例public synchronized void instanceLock() { // code}// 关键字在静态方法上,锁为当前Class对象public static synchronized void classLock() { // code}// 关键字在代码块上,锁为括号里面的对象/类public void blockLock() { Object o = new Object(); synchronized (o) { // code }}// 当然除此之外,我们还可以使用 this 对象(代表当前实例)或者当前类的 Class 对象作为锁如果 synchronized 关键字在方法上,那临界区就是整个方法内部;如果使用 synchronized 代码块,那临界区就是代码块内部的区域。
当一个线程进入到同步代码块时,会获取到当前的锁,而这时如果其他使用同样的锁的同步代码块也想执行内容,就必须等待当前同步代码块的内容执行完毕自动释放这把锁,其他的线程才能拿到这把锁并开始执行同步代码块里面的内容(实际上synchronized是一种悲观锁,随时都认为有其他线程在对数据进行修改,后面会讲到乐观锁,如CAS算法)。
synchronized 属于可重入锁,可以一定程度避免死锁:
- 从互斥锁的设计上来说,当一个线程试图操作一个由其他线程持有的对象锁的临界资源时,将会处于阻塞状态,但当一个线程再次请求自己持有对象锁的临界资源时,这种情况属于重入锁,请求将会成功。
- synchronized 就是可重入锁,因此一个线程调用 synchronized 方法的同时,在其方法体内部调用该对象另一个 synchronized 方法是允许的,如下:
public class AccountingSync implements Runnable{ static AccountingSync instance=new AccountingSync(); static int i=0; static int j=0;
@Override public void run() { for(int j=0;j<1000000;j++){ //this,当前实例对象锁 synchronized(this){ i++; increase();//synchronized的可重入性 } } }
public synchronized void increase(){ j++; }
public static void main(String[] args) throws InterruptedException { Thread t1=new Thread(instance); Thread t2=new Thread(instance); t1.start();t2.start(); t1.join();t2.join(); System.out.println(i); }}Java对象头#
一个对象的“锁”的信息存放在什么地方呢?
每个Java对象都有对象头。如果是非数组类型,则用2个字宽(1个字宽为32/64bit)来存储对象头;如果是数组类型,则用3个字宽。
对象头的内容:
- 普通对象(非数组):对象头通常由 2 个字宽(word) 组成:
- Mark Word(1 word):存储哈希码、GC 分代年龄、锁状态等。
- Klass Word(1 word):指向对象所属类的元数据(即 Class 对象)。
- 数组对象:对象头由 3 个字宽 组成:
- Mark Word(1 word)
- Klass Word(1 word)
- Array Length(1 word):额外存储数组的长度。
主要来看Mark Word的格式:


可以看到,当对象状态为偏向锁时, Mark Word 存储的是偏向的线程ID;当状态为轻量级锁时, Mark Word 存储的是指向线程栈中 Lock Record 的指针;当状态为重量级锁时, Mark Word 为指向堆中的monitor对象的指针。
对象监视器 monitor#
拿同步块来举例:
static int counter = 0;
public static void main(String[] args) { synchronized (lock) { counter++; }}经过 javap -v 编译后的指令如下:
public static void main(java.lang.String[]); // 方法签名 descriptor: ([Ljava/lang/String;)V // 访问修饰符 flags: ACC_PUBLIC, ACC_STATIC
Code: // 操作数栈深度和本地变量表容量 stack=2, locals=3, args_size=1 0: getstatic #2 // Field lock:Ljava/lang/Object; // 获取静态字段 lock 的值并将其推送到操作数栈顶部 3: dup // 复制栈顶的数值(即 lock 引用)并将副本推送到操作数栈顶部 4: astore_1 // 将栈顶的数值(即 lock 引用的副本)存储到本地变量 1(args 参数) 5: monitorenter // 进入监视器(锁)保护的同步块 6: getstatic #3 // Field counter:I 执行counter++ 9: iconst_1 10: iadd 11: putstatic #3 14: aload_1 15: monitorexit // 自增操作完毕,退出监视器(锁)保护的同步块 16: goto 24 // 无条件跳转到指令位置 24,继续执行下面的指令 19: astore_2 // 这里是异常处理:将栈顶的数值(即异常对象引用)存储到本地变量 2(ex 异常) 20: aload_1 // 将本地变量 1(args 参数)加载到操作数栈顶部 21: monitorexit // 释放锁:在异常处理块中,退出监视器(锁)保护的同步块 22: aload_2 // 重试异常:将本地变量 2(ex 异常)加载到操作数栈顶部 23: athrow // 抛出异常 24: return // 方法返回
Exception table: from to target type 6 16 19 any // 如果6~16行出现了异常,跳转到19行继续执行 19 22 19 any // 如果19~22行出现了异常,跳转到19行继续执行
monitorenter指令在编译后会插入到同步代码块的开始位置;monitorexit指令会插入到方法结束和抛出异常(但被 finally 或外层 catch 处理)的位置;- 当一个线程执行到
monitorenter指令时,就会获得对象所对应 monitor的所有权,也就获得到了对象的锁。
每个对象都可以关联一个Monitor对象,使用synchronized给对象上锁(重量级)之后,该对象头的MarkWord就被指向Monitor对象的指针。
注意:不加synchronized的对象不会关联监视器

class ObjectMonitor { void* _owner; // 当前持有者 int _recursions; // 重入次数 int _count; // (部分版本保留)
ObjectWaiter* _cxq; // contention queue/list,并发竞争栈(LIFO) ObjectWaiter* _EntryList; // 阻塞等待链表 ObjectWaiter* _WaitSet; // wait() 等待链表
Thread* _succ; // 下一个候选继承者 Thread* _Responsible; // 自旋线程 oop _object; // 关联的 Java 对象 ObjectMonitor* _FreeNext; // 空闲链表指针
volatile int _flags; // 状态标志};Monitor 核心字段包含:
_owner:当前持有锁的线程;_count:重入计数;_EntryList:一个双向链表,存放等待获取锁的线程队列;_WaitSet:一个双向链表,存放因调用obj.wait()而主动放弃锁并等待通知的WAITING状态线程。
几种锁#
Java 6 为了减少获得锁和释放锁带来的性能消耗,引入了“偏向锁”和“轻量级锁“。
在Java 6 以前,所有的锁都是”重量级“锁。所以在Java 6 及其以后,一个对象其实有四种锁状态,它们级别由低到高依次是:
- 无锁状态
- 偏向锁状态
- 轻量级锁状态
- 重量级锁状态
无锁就是没有对资源进行锁定,任何线程都可以尝试去修改它。
几种锁会随着竞争情况逐渐升级,重量级锁不能撤销或降级回偏向锁或轻量级锁。
- 在 JDK 6 ~ JDK 15(默认开启偏向锁)
- 锁状态:无锁 → 偏向锁 → 轻量级锁 → 重量级锁;
- 多线程竞争会先撤销偏向锁,再尝试轻量级锁,最后才膨胀。
- JDK 15+(偏向锁默认禁用):偏向锁升级成轻量级锁时,会暂停拥有偏向锁的线程,重置偏向锁标识,这个过程开销很大
- 直接:无锁 → 轻量级锁 → 重量级锁。
各种锁的优缺点对比(来自《Java 并发编程的艺术》):
| 锁 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| 偏向锁 | 加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距。 | 如果线程间存在锁竞争,会带来额外的锁撤销的消耗。 | 适用于只有一个线程访问同步块场景。 |
| 轻量级锁 | 竞争的线程不会阻塞,提高了程序的响应速度。 | 如果始终得不到锁竞争的线程使用自旋会消耗 CPU。 | 追求响应时间。同步块执行速度非常快。 |
| 重量级锁 | 线程竞争不使用自旋,不会消耗 CPU。 | 线程阻塞,响应时间缓慢。 | 追求吞吐量。同步块执行时间较长。 |
轻量级锁#
针对多个线程在不同时段获取同一把锁,即不存在锁竞争、没有线程阻塞的情况,JVM采用轻量级锁来避免线程的阻塞与唤醒。
1、轻量级锁的加锁
- 每个线程在执行
synchronized时,会在当前 Java 栈帧(stack frame)中分配一个 Lock Record; - 它是一个固定大小的内存槽(slot),通常包含两个字段(简化模型):
struct LockRecord {uintptr_t displaced_header; // ← 这就是 "Displaced Mark Word"oop obj; // (可选)指向被锁对象的指针};
- 当线程获取轻量级锁时:
- 将对象头中的 Mark Word 复制出来,存入 Lock Record 的
displaced_header字段; - 这个被复制出来的 Mark Word 副本就叫 Displaced Mark Word(“被置换出的 Mark Word”);
- 将对象头中的 Mark Word 复制出来,存入 Lock Record 的
- 随后,JVM 尝试用 CAS 将 Lock Record 的地址 写入对象头
- 如果成功,表示这是当前线程首次获得锁
- 如果失败,有两种情况,
- 一种是当前线程多次进入同一个 synchronized 块(即重入),那么再分配一个新的 Lock Record,但将其
displaced_header设为NULL; - 另一种是表示Mark Word已经被替换成了其他线程的锁记录,说明在与其它线程竞争锁,当前线程就尝试使用自旋来获取锁。
- 一种是当前线程多次进入同一个 synchronized 块(即重入),那么再分配一个新的 Lock Record,但将其
自旋:不断尝试去获取锁,一般用循环来实现。
自旋是需要消耗CPU的,如果一直获取不到锁的话,那该线程就一直处在自旋状 态,浪费CPU资源。可以指定自旋的次数,但是HotSpot JVM 采用 适应性自旋(Adaptive Spinning) 机制:
- 它基于每个锁对象的历史竞争情况动态调整自旋策略;
- 如果某锁过去容易通过自旋获得(持有时间短),则增加自旋次数;
- 如果自旋经常失败(竞争激烈或持有时间长),则减少甚至跳过自旋,直接进入阻塞;
- 目的是在 CPU 开销 和 线程挂起开销 之间取得最佳平衡。
2、锁膨胀
如果自旋到一定程度依然没有获取到锁,称为自旋失败,那么这个线程会阻塞,同时这个锁会升级成重量级锁。
目的是:避免长时间自旋浪费 CPU,转而使用 OS 提供的阻塞/唤醒机制,提高系统整体效率。
- 创建重量级 Monitor 对象
- JVM 在堆外(C++ 层)分配一个
ObjectMonitor实例;
- JVM 在堆外(C++ 层)分配一个
- 将对象头指向 Monitor
- 使用 CAS 将对象头的 Mark Word 替换为指向
ObjectMonitor的指针; - 此后,所有新来的线程发现对象头指向 Monitor,
synchronized操作都走重量级锁逻辑。
- 使用 CAS 将对象头的 Mark Word 替换为指向
- 挂起竞争线程
- 触发膨胀的线程(如线程 B)不再自旋;
- 调用 OS 的阻塞原语(如 Linux 的
pthread_mutex_lock/futex); - 被加入 Monitor 的
_cxq(Contention List),进入 OS 睡眠状态(S); - 等待锁持有者释放锁后被唤醒。
3、轻量级锁的释放
退出synchronized代码块(解锁)时,
- 如果有取值为null的锁记录,表示有重入,此时删除锁记录,表示重入计数-1
- 如果锁记录的值不为null,此时使用CAS将MarkWord的值恢复给对象头
- 成功,说明没有发生竞争,轻量级锁仍然有效,解锁完成
- 失败,说明轻量级锁进行了锁膨胀或已经升级为重量级锁,此时,JVM 会转入重量级锁的解锁流程
- 调用 OS 的 mutex 解锁原语;
- 唤醒 Entry Set 中等待的线程(即之前因竞争失败而被阻塞的线程)。

重量级锁#
重量级锁依赖于操作系统的互斥量(mutex) 实现,而操作系统中线程间状态的转换需要相对比较长的时间,所以重量级锁效率很低,但被阻塞的线程不会消耗CPU。
注意:一旦对象真正进入重量级锁状态(Mark Word 指向
ObjectMonitor),后续线程不再自旋,而是直接阻塞。
加锁: ┌───────────────┐ │ 尝试 CAS 抢锁 │ ← 新线程 or 自旋成功 └───────┬───────┘ ↓ 否 ┌───────────────┐ │ 是否重入? │ └───────┬───────┘ ↓ 否 ┌───────────────┐ │ 插入 _cxq │ ← CAS 入栈 └───────┬───────┘ ↓ ┌───────────────┐ │ park() 挂起 │ └───────────────┘
释放锁: ┌───────────────┐ │ 重入?→ 递减 │ └───────┬───────┘ ↓ 否 ┌───────────────┐ │ 合并 _cxq → _EntryList │ └───────┬───────┘ ↓ ┌───────────────┐ │ 选 succ(假定继承人)│ └───────┬───────┘ ↓ ┌───────────────┐ │ unpark(succ) │ └───────────────┘ ↓ succ 线程回到“加锁”流程顶部,重新抢锁一、重量级锁加锁流程(ObjectMonitor::enter)
步骤 1:快速尝试直接获取锁
if (monitor->_owner == NULL) { // CAS 尝试直接抢锁 if (Atomic::cmpxchg(&monitor->_owner, NULL, current_thread) == NULL) { return; // 成功! }}步骤 2:检查是否重入(当前线程已持有)
if (monitor->_owner == current_thread) { monitor->_recursions++; // 重入计数 +1 return}步骤 3:进入竞争队列(_cxq)
- 将当前线程封装为
ObjectWaiter; - 通过 CAS 原子地插入到
_cxq(Contention List)的头部(LIFO 栈结构); _cxq是一个无锁并发栈,避免多线程同时修改_EntryList的锁竞争。
步骤 4:挂起线程(park)
- 调用
os::PlatformEvent::park()(底层是pthread_cond_wait或futex); - 线程进入 OS 阻塞状态(
BLOCKED),不消耗 CPU;
二、重量级锁释放流程(ObjectMonitor::exit)
步骤 1:处理重入
if (monitor->_recursions > 0) { monitor->_recursions--; return; // 未完全释放}步骤 2:准备唤醒候选线程
JVM 会按优先级检查以下位置是否有等待线程:
_EntryList(主等待队列)_cxq(并发竞争栈)_succ(假定继承人,若有)
合并 _cxq 到 _EntryList
- 将
_cxq中的所有线程原子地转移到_EntryList尾部; - 此时
_EntryList包含所有等待线程。
步骤 3:选择 “Heir Presumptive”(假定继承人)
- 从
_EntryList头部取出一个线程(通常是最早进入的); - 设置为
_succ(successor),但此时并不立即唤醒它!
步骤 4:尝试“锁交接优化”
- 如果
_succ存在,JVM 可能:- 直接将
_owner设为_succ线程(无需唤醒+竞争); - 或仅设置
_succ,让其稍后被唤醒。
- 直接将
步骤 5:唤醒线程
- 调用
unpark(succ)唤醒假定继承人; - 被唤醒的线程从
park()返回,重新进入enter流程(尝试 CAS 抢锁)。
⚠️ 非公平性的体现:
- 在
succ被唤醒之前,可能有新来的线程通过自旋或 CAS 抢先获得锁;- 因此,
_EntryList中的线程不能保证先到先得 → synchronized 是非公平锁。
三、wait() / notify() 与 Monitor 的交互
Object类有三个方法,分别是 wait()、notify() 以及 notifyAll(),他们其实是需要配合synchronized来使用的(实际上锁就是依附于对象存在的,每个对象都应该有针对于锁的一些操作,所以这样设计),只有在同步代码块中才能使用这些方法,正常情况下会报错。
调用 obj.wait()
- 必须已持有锁;
- 将当前线程加入
_WaitSet; - 释放锁(调用
exit); - 调用
park()挂起(状态变为WAITING)。
调用 obj.notify()
- 从
_WaitSet移出一个WAITING状态的线程; - 将其加入
_cxq; - 不立即唤醒,等下次
exit时统一处理。
所以:
notify唤醒的线程,和其他竞争线程一样,要走_cxq→_EntryList→ 抢锁 的流程。
notifyAll其实和notify一样,也是用于唤醒,但是前者是唤醒所有调用 wait() 后处于等待的线程,而后者是随机选择一个。
注意区别:
BLOCKED状态的线程:是因为尝试进入synchronized块但发现锁已被占用,于是被加入_cxq,处于阻塞等待状态。WAITING状态的线程:是主动调用wait()放弃锁并进入_WaitSet,只有被notify/notifyAll唤醒后才会被移到_cxq,之后和其他竞争者一样走抢锁流程。
偏向锁#
轻量级锁在没有竞争时,每次重入仍需要进行CAS操作。Java6 中引入了偏向锁来减少无竞争场景下的同步开销:只有第一次使用CAS将线程ID设置到对象头的MarkWord头,之后发现这个线程ID是自己的,那么就表示没有竞争,不用任何CAS或原子操作。以后只要不发生竞争,这个对象就归该线程所有。
值得注意的是,如果对象通过调用
hashCode()方法计算过对象的一致性哈希值,那么它是不支持偏向锁的,会直接进入到轻量级锁状态,因为Hash是需要被保存的,而偏向锁的Mark Word数据结构,无法保存Hash值;如果对象已经是偏向锁状态,再去调用hashCode()方法,那么会直接将锁升级为重量级锁,并将哈希值存放在monitor(有预留位置保存)中。
一、偏向锁加锁流程(biased_locking_enter)
场景:线程 A 第一次进入 synchronized(obj)
- 步骤 1:检查对象头是否为可偏向状态
- Mark Word 格式为:
[hashCode | age | 101](未锁定、可偏向); - 如果已计算
hashCode()→ 直接走轻量级锁(因无空间存 thread ID)。
- Mark Word 格式为:
- 步骤 2:执行 CAS 原子操作,将 Mark Word 替换为:
[epoch | thread ID (A) | age | 101]
- 成功 → 偏向线程 A,记录在对象头;
- 失败 → 可能有其他线程也在竞争尝试 CAS 将初始 Mark Word(无锁状态)改为各自线程 ID 的偏向锁,由于 CAS 原子性保证,只有一个能成功,失败的那个线程(比如 A)就会 CAS 失败,进入撤销偏向(bias revocation) 流程。
场景:线程 A 再次进入 synchronized(obj)
步骤:
- 读取对象头 Mark Word;
- 检查 thread ID 是否等于当前线程 ID;
- 如果是 → 直接进入临界区,无任何 CAS、无任何原子操作;
- 如果不是 → 触发偏向撤销。
二、当其他线程(B)尝试竞争时:偏向撤销(Bias Revocation)
- 线程 B 发现对象偏向线程 A(Mark Word 中 thread ID ≠ B);
- 线程 B 触发“偏向撤销”:
- 向 JVM 提交一个
Revocation Task; - JVM 在安全点(Safepoint) 暂停所有线程;
- 检查线程 A 的状态:
- 如果线程 A 已退出所有同步块(逻辑上不持有该锁,但物理上仍持有):
- 将对象重新偏向线程 B(更新 thread ID);
- 锁仍为偏向锁;
- 如果线程 A 仍在同步块中(仍逻辑持有该锁):
- 撤销偏向:清除 thread ID,设置 Mark Word 为
[hashCode | age | 001](无锁); - 后续加锁走轻量级锁路径;
- 不会立即升级为轻量级锁,而是下次加锁时按无锁处理。
- 撤销偏向:清除 thread ID,设置 Mark Word 为
- 如果线程 A 已退出所有同步块(逻辑上不持有该锁,但物理上仍持有):
- 向 JVM 提交一个
三、偏向锁没有“释放”操作,而是使用了一种等到竞争出现才释放锁的机制
- 线程 A 退出
synchronized块时:- 不做任何事(不修改 Mark Word);
- 对象头仍然保留 thread ID = A;
- 只有当下次其他线程竞争时,才通过 Safepoint 撤销。
线程 A 首次 synchronized(obj) ↓CAS 设置 Mark Word = [epoch | A | age | 101] → 偏向锁建立
线程 A 再次进入 ↓检查 thread ID == A → 直接进入(零开销)
线程 B 尝试 synchronized(obj) ↓发现 thread ID ≠ B → 触发 Bias Revocation ↓JVM 在 Safepoint 暂停所有线程 ↓检查线程 A 是否仍在同步块? ├─ 否 → 重新偏向 B(仍为偏向锁) └─ 是 → 撤销偏向,Mark Word = [hash | age | 001] ↓ 下次加锁走轻量级锁流程八、乐观锁与CAS(Compare-And-Swap)#
CAS(Compare-And-Swap,比较并交换)是一种乐观锁的实现方式,用于在硬件层面上提供无锁的原子性操作。比较是否和给定的数值一致,如果一致则修改,不一致则不修改。
乐观锁与悲观锁#
synchronized是悲观锁,它总是认为每次访问共享资源时会发生冲突,所以必须对每次数据操作加上锁,以保证临界区的程序同一时间只能有一个线程在执行;- 悲观锁多用于”写多读少“的环境,避免频繁失败和重试影响性能;
CAS是乐观锁,总是假设对共享资源的访问没有冲突,线程可以不停地执行,无需加锁也无需等待。一旦多个线程发生冲突,乐观锁通常使用一种称为 CAS 的技术来保证线程执行的安全性;- 乐观锁多用于“读多写少“的环境,避免频繁加锁影响性能。
由于乐观锁假想操作中没有锁的存在,因此不太可能出现死锁的情况,换句话说,乐观锁天生免疫死锁。
CAS 原理#
在 CAS 中,有这样三个值:
- V:要更新的变量(var)
- E:预期值(expected),本质上指的是**“旧值”**
- N:新值(new)
比较并交换的过程:判断 V 是否等于 E,如果等于,将 V 的值设置为 N;如果不等,说明已经有其它线程更新了 V,于是当前线程放弃更新,什么都不做。
有没有可能在判断了V为E之后,正准备更新它为N时,被其它线程更改了V的值呢?
不会的。因为 CAS 是一种原子操作,它是一种系统原语,是一条 CPU 的原子指令,从 CPU 层面已经保证它的原子性。
当多个线程同时使用 CAS 操作一个变量时,只有一个会胜出,并成功更新,其余均会失败,但失败的线程并不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。
在 Java 中,如果一个方法是 native 的,那 Java 就不负责具体实现它,而是交给底层的 JVM 使用 C 或者 C++ 去实现。
在 Java 中有一个 Unsafe 类,在 sun.misc 包中,里面都是 native 方法,其中就有几个是关于 CAS 的:
boolean compareAndSwapObject(Object o, long offset,Object expected, Object x);boolean compareAndSwapInt(Object o, long offset,int expected,int x);boolean compareAndSwapLong(Object o, long offset,long expected,long x);Linux 的 X86 下主要是通过 cmpxchgl 这个指令在 CPU 上完成 CAS 操作,但在多处理器情况下,必须使用 lock 指令加锁来完成。当然,不同的操作系统和处理器在实现方式上肯定会有所不同。
CMPXCHG是“Compare and Exchange”的缩写,它是一种原子指令,用于在多核/多线程环境中安全地修改共享数据。CMPXCHG在很多现代微处理器体系结构中都有,例如Intel x86/x64体系。对于32位操作数,这个指令通常写作CMPXCHG,而在64位操作数中,它被称为CMPXCHG8B或CMPXCHG16B。
CAS 如何实现原子操作#
上面介绍了 Unsafe 类的支持 CAS 的方法。那 Java 具体是如何通过这几个方法来实现原子操作的呢?
JDK 提供了一些用于原子操作的类,在java.util.concurrent.atomic包下面。
这里以 AtomicInteger 类的 getAndAdd(int delta) 方法为例。
public final int getAndAdd(int delta) { return unsafe.getAndAddInt(this, valueOffset, delta);}这里的 unsafe 其实就是一个 Unsafe 对象:
// setup to use Unsafe.compareAndSwapInt for updatesprivate static final Unsafe unsafe = Unsafe.getUnsafe();所以,AtomicInteger 类的 getAndAdd() 方法是通过调用 Unsafe 类的方法实现的:
public final int getAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4));
return var5;}- Object var1,这个参数代表你想要进行操作的对象。
- long var2,这个参数是你想要操作的 var1 对象中的某个字段的偏移量。这个偏移量可以通过 Unsafe 类的 objectFieldOffset 方法获得。
- int var4,这个参数是你想要增加的值。
方法执行的过程:
- 首先,在 do while 循环开始,通过
this.getIntVolatile(var1, var2)获取当前对象指定字段的值,将其存入临时变量 var5 中。这里的 getIntVolatile 方法能保证读操作的可见性,即读取的结果是最新的写入结果,不会因为 JVM 的优化策略或者 CPU 的缓存导致读取到过期的数据。 - 然后,执行
compareAndSwapInt(var1, var2, var5, var5 + var4)进行 CAS 操作。如果对象 var1 在内存地址 var2 处的值等于预期值 var5,则将该位置的值更新为 var5 + var4,并返回 true;否则,不做任何操作并返回 false。 - 如果 CAS 操作成功,说明我们成功地将 var1 对象的 var2 偏移量处的字段的值更新为 var5 + var4,并且这个更新操作是原子性的,因此我们跳出循环并返回原来的值 var5。
- 如果 CAS 操作失败,说明在我们尝试更新值的时候,有其他线程修改了该字段的值,所以我们继续循环,重新获取该字段的值,然后再次尝试进行 CAS 操作。
这里使用的是do-while 循环,目的是保证循环体内的语句至少会被执行一遍。
CAS 的三大问题#
ABA 问题#
ABA 问题是指在基于 CAS(Compare-And-Swap)的无锁算法中,一个变量的值从 A → B → A 变化后,CAS 操作仍会认为“值未变”,从而错误地认为期间没有发生任何修改。 但实际上,该变量已经被其他线程修改过两次,可能已导致逻辑不一致(例如链表节点被删除又复用)。
📌 典型场景: 在无锁栈(Lock-Free Stack)中,线程1准备弹出节点 A;此时线程2弹出 A,再压入新节点(恰好地址复用为 A),线程1的 CAS 成功,但实际弹出了“另一个 A”,造成数据错乱。
ABA 问题的解决思路是在变量前面追加上版本号或者时间戳。从 JDK 1.5 开始,JDK 的 atomic 包里提供了 AtomicStampedReference 类来解决引用类型的 ABA 问题。(注:对于基本类型,可使用 AtomicMarkableReference 或自定义带版本字段的包装类)
这个类的 compareAndSet 方法的作用是首先检查当前引用是否等于预期引用,并且检查当前标志是否等于预期标志,如果二者都相等,才使用 CAS 设置为新的值和标志。
public boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp) { Pair<V> current = pair; return expectedReference == current.reference && expectedStamp == current.stamp && ((newReference == current.reference && newStamp == current.stamp) || casPair(current, Pair.of(newReference, newStamp)));}- expectedReference:期望的当前引用值
- newReference:更新后的引用值
- expectedStamp:期望的当前版本戳
- newStamp:更新后的版本戳
执行流程:
1、Pair<V> current = pair;
pair是一个 volatile 的Pair对象,包含reference和stamp;- 由于
pair在AtomicMarkableReference类中被定义为 volatile,可以保证读取的是最新值(happens-before 语义)。
2、双重校验 expectedReference == current.reference && expectedStamp == current.stamp(使用 == 比较引用)
3、短路优化:无需更新 (newReference == current.reference && newStamp == current.stamp)
- 如果新值与当前值完全相同,则跳过 CAS 操作,直接返回
true。 - 避免不必要的内存写入和缓存行失效,提升性能。
4、执行 CAS 更新 casPair(current, Pair.of(newReference, newStamp))
- 调用底层 Unsafe.compareAndSwapObject 尝试原子地将 pair 从 current 替换为新 Pair。
- 若成功,返回 true;若失败(因其他线程并发修改),返回 false,由调用方决定是否重试。
长时间自旋#
CAS 多与自旋结合。如果自旋 CAS 长时间不成功,会占用大量的 CPU 资源。
解决思路是让 JVM 支持处理器提供的pause 指令。
pause 指令能让自旋失败时 cpu 睡眠一小段时间再继续自旋,从而使得读操作的频率降低很多,为解决内存顺序冲突而导致的 CPU 流水线重排的代价也会小很多。
多个共享变量的原子操作#
当对一个共享变量执行操作时,CAS 能够保证该变量的原子性。但是对于多个共享变量,CAS 就无法保证操作的原子性,这时通常有两种做法:
- 使用
AtomicReference类保证对象之间的原子性,把多个变量放到一个对象里面进行 CAS 操作; - 使用锁,锁内的临界区代码可以保证只有当前线程能操作。